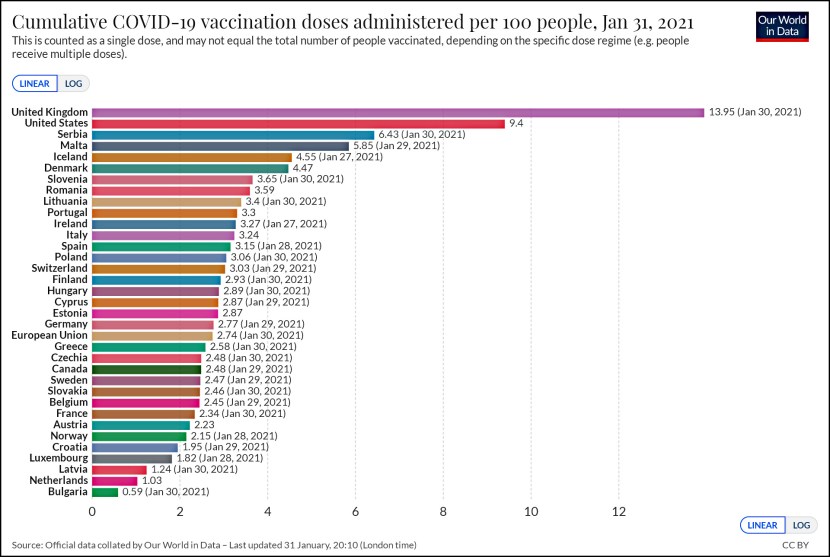
I got an email today from a regular reader asking why I didn’t seem to be much worried about all the glitches in Tuesday’s Obamacare rollout. And it’s true: I mentioned it briefly  yesterday but didn’t treat it like a big deal. Why?
yesterday but didn’t treat it like a big deal. Why?
I can’t say for sure. But the answer probably lies in my background. I’m not an expert in rolling out massive software systems or anything, but I have been involved in dozens of big software launches in my life. And every one of them has gone exactly the same:
- Lots of smart people work really hard for a really long time.
- The launch is late anyway.
- When it does happen, the product has a bunch of bugs.
- Sometimes the bugs are really serious. If so, everyone panics and works their asses off for a while to fix them. Pretty soon, they get fixed and everyone moves on to whatever’s next on the crisis agenda.
- Lather, rinse, repeat.
So….I dunno. I’ve seen this movie too many times before. Traffic on the Obamacare sites will settle down pretty quickly, and that will take care of most of the overloading problems. The remaining load problems will be solved with software fixes or by allocating more servers. Bugs will be reported and categorized. Software teams will take on the most serious ones first and fix most of them in short order. Before long, the sites will all be working pretty well, with only the usual background rumble of small problems. By this time next month, no one will even remember that the first week was kind of rocky or that anyone was initially panicked.
I might be wrong. I’ve been involved in a few rollouts that featured really serious bugs that took a long time to work out. It’s certainly possible that one or two states will fall into this category. But I doubt it. Technologically speaking, nothing that happened yesterday surprised me, and I don’t expect anything in the next month to surprise me much either.
UPDATE: A friend with more experience than me in this particular kind of software development emails to explain in more detail why the Obamacare rollout glitches are probably not very serious:
It’s because this exact product has been built thousands of times….It’s a bunch of forms on top of a bunch of conditional SQL. Nothing new, or innovative, or especially challenging. The problems are simply because of the scale, and with Google and Facebook and Twitter and the like, we’ve figured out how to do web-scale pretty well.
The “bugs” will be in the Java and SQL code, and they’ll be easy to fix. Everything else is just web-scale infrastructure, memcached and database tuning, load balancing, edge routing, nuts & bolts stuff. I’ve never been worried about it at all, because it’s just plain been done so many times before. Not exactly uncharted technological waters.
For what it’s worth, I’ll say this: If there are still lots of serious problems with these websites on November 1, I’ll eat crow. But I doubt that I’ll have to.